Mixture-of-Experts là gì? Giải thích dễ hiểu cho Developer
24 Jun, 2025
Hướng nội
AuthorMixture-of-Experts là kiến trúc mạng nơ-ron gồm nhiều mạng con (expert), mỗi expert chuyên xử lý một kiểu nhiệm vụ hoặc loại dữ liệu cụ thể

Mục Lục
Trong những năm gần đây, Mixture-of-Experts (MoE) đã nổi lên như một kiến trúc đột phá, đóng vai trò then chốt trong việc phát triển các mô hình trí tuệ nhân tạo quy mô cực lớn. Những cái tên như GPT, Mixtral, DeepSeek hay Google Gemini đều tận dụng sức mạnh của MoE để đạt được khả năng mở rộng và tối ưu hiệu suất vượt trội.
Bài viết này sẽ trình bày lịch sử hình thành và nguyên lý hoạt động của Mixture-of-Experts dưới góc nhìn của Developer, giúp bạn dễ dàng tiếp cận và nắm bắt các khái niệm cốt lõi.
1. Lịch sử ra đời của Mixture-of-Experts (MoE)
Để hiểu tại sao MoE lại đột phá đến vậy, chúng ta cần quay ngược thời gian về năm 1991. Khi đó, các huyền thoại trong ngành AI là Geoffrey Hinton, Robert Jacobs, và Michael Jordan đã xuất bản một bài báo có tên "Adaptive Mixtures of Local Experts".
Mục tiêu ban đầu của họ khá giống với các kỹ thuật ensemble learning khác: thay vì cố gắng tạo ra một mô hình hoàn hảo, tại sao không kết hợp sức mạnh của nhiều mô hình nhỏ hơn, chuyên biệt hơn? Ý tưởng chính là "chia để trị": một nhiệm vụ phức tạp có thể được chia thành các bài toán con đơn giản hơn, và mỗi "chuyên gia" (expert) sẽ chỉ học cách giải quyết một trong số các bài toán con đó. Một "nhà quản lý" (gating network) sẽ học cách định tuyến vấn đề đến đúng chuyên gia.
Dù ý tưởng “chia để trị” này rất thú vị, nhưng trong suốt gần ba thập kỷ sau đó, MoE vẫn chỉ dừng lại ở phạm vi học thuật. Nguyên nhân chủ yếu là do công nghệ thời bấy giờ còn nhiều hạn chế: sức mạnh phần cứng không đáp ứng được nhu cầu vận hành các mạng lưới phức tạp với nhiều “chuyên gia”, dữ liệu đầu vào chưa đủ lớn và đa dạng để chuyên môn hóa phát huy tác dụng, đồng thời những mô hình mạng nơ-ron khác đơn giản hơn lại hoạt động hiệu quả trên các bài toán quy mô nhỏ, lấn át MoE trong thực tế.
MoE gần như bị “ngủ quên” cho đến thời điểm các mô hình Transformer và LLM xuất hiện. Lúc đó, các nhà nghiên cứu tại Google, OpenAI cùng nhiều tổ chức khác bắt đầu chạm tới giới hạn mở rộng của dense model – khi chi phí và tài nguyên tăng vọt theo kích thước mô hình. Đến năm 2017, Google công bố bài báo “Outrageously Large Neural Networks”, không chỉ hồi sinh MoE mà còn áp dụng thành công ý tưởng này vào các mô hình ngôn ngữ lớn, chứng minh tiềm năng mở rộng vượt trội so với trước đây.
2. Mixture-of-Experts là gì?
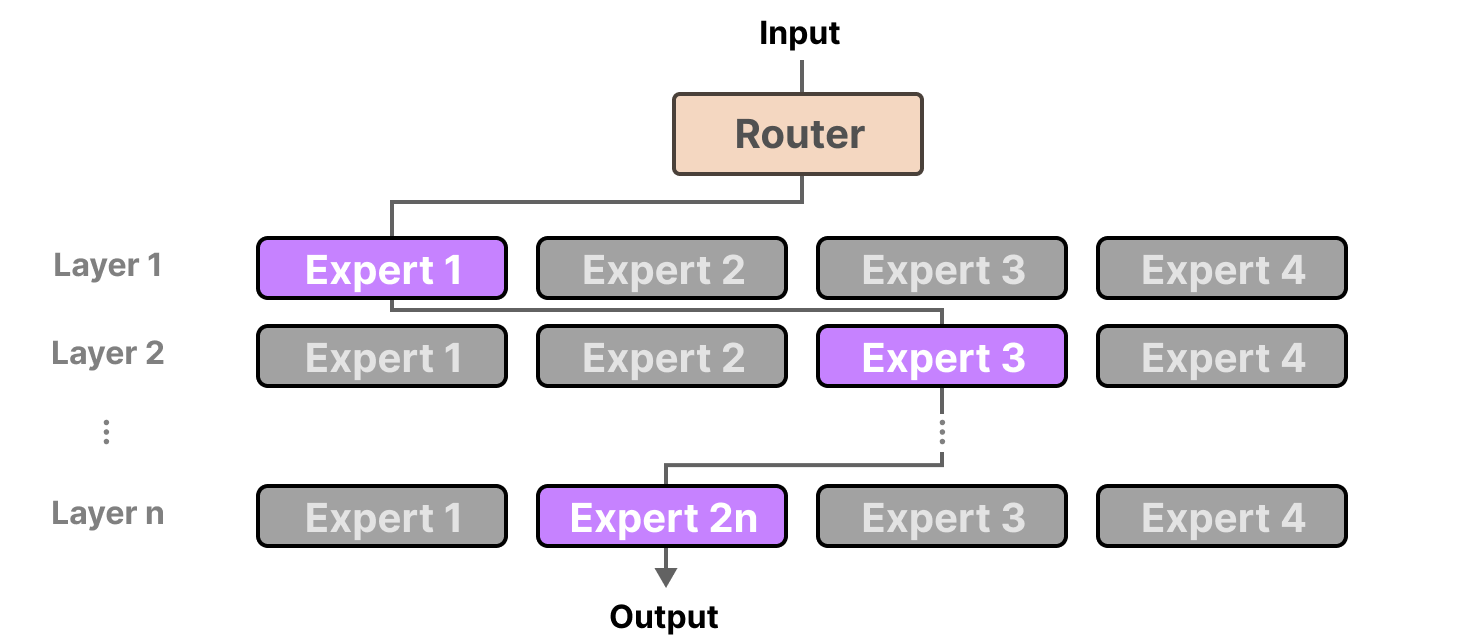
Mixture-of-Experts (MoE) là một kiến trúc mạng nơ-ron hoạt động theo nguyên tắc chia để trị. Thay vì dùng một mô hình khổng lồ, MoE sử dụng hai thành phần chính:
- Nhiều "Chuyên gia" (Experts): Các mạng nơ-ron nhỏ hơn, mỗi mạng được huấn luyện để chuyên xử lý các loại dữ liệu hoặc tác vụ khác nhau (ví dụ: một chuyên gia giỏi về code, một chuyên gia giỏi về văn học).
- Một "Bộ định tuyến" (Gating Network / Router): Một mạng nơ-ron nhỏ có nhiệm vụ xem xét dữ liệu đầu vào (ví dụ: một token) và quyết định một cách linh động xem nên gửi nó đến chuyên gia nào phù hợp nhất.
Nhờ vậy, mô hình có thể sở hữu lượng kiến thức khổng lồ (tổng tham số lớn) nhưng tốc độ xử lý vẫn nhanh như một mô hình nhỏ hơn nhiều.
Hãy tưởng tượng cấu trúc của một doanh nghiệp thông thường để dễ hình dung. Trong một dense model thông thường, mọi yêu cầu – từ việc nhỏ như sửa máy in cho đến chốt những hợp đồng lớn – đều phải trình lên toàn bộ ban giám đốc. Dù vấn đề chẳng liên quan đến chuyên môn của hầu hết các giám đốc, tất cả vẫn phải tham gia, gây ra sự lãng phí lớn về thời gian và nguồn lực.
Ngược lại, MoE giống như một công ty hoạt động hiệu quả hơn rất nhiều. Tại đây, ngoài ban giám đốc (chính là các "expert"), còn có một “thư ký điều phối” cực kỳ thông minh (tức là Gating Network hay Router). Khi có một vấn đề được gửi tới (input token), thư ký này sẽ phân tích: “Vấn đề này thuộc về lĩnh vực tài chính và kỹ thuật, vậy hãy mời Giám đốc Tài chính và Giám đốc Công nghệ tham gia họp.” Những giám đốc còn lại được tự do làm việc riêng, không bị làm phiền bởi các vấn đề ngoài chuyên môn.
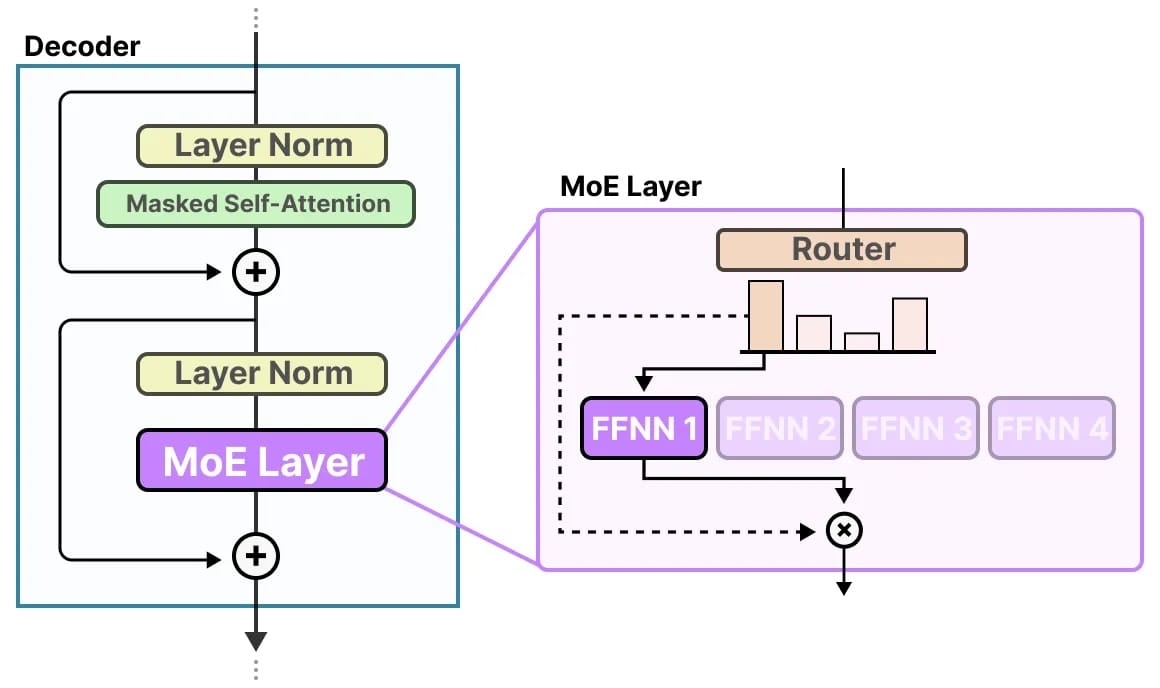
Về mặt kiến trúc, một layer MoE thường được dùng để thay thế cho layer Feed-Forward Network (FFN) truyền thống trong mô hình Transformer. Layer này cơ bản gồm hai thành phần chính:
- Tập hợp N "Expert": Mỗi expert là một mạng nơ-ron độc lập (thường là một FFN chuẩn), đóng vai trò như một chuyên gia thực thụ. Ví dụ, trong Mixtral 8x7B, mỗi layer MoE có 8 experts.
- Một Gating Network (Router): Là một mạng nơ-ron nhỏ, đảm nhận nhiệm vụ chọn ra những expert phù hợp để xử lý từng token đầu vào.
Điểm khác biệt then chốt là: ở dense model, tất cả tham số của FFN đều được sử dụng với mọi input token. Nhưng với MoE, chỉ có các tham số của Gating Network và các experts được chọn (chẳng hạn 2 trong số 8) mới tham gia vào quá trình xử lý, giúp tiết kiệm tài nguyên và gia tăng hiệu suất đáng kể.
3. Bên trong Ma trận của MoE Layer
Bây giờ, chúng ta sẽ cùng xem xét các phép toán ma trận thực sự diễn ra bên trong. Giả sử chúng ta có mộttoken đầu vào được biểu diễn bằng vector x.
Gating Network sẽ thực hiện một công việc tưởng chừng đơn giản nhưng lại vô cùng phức tạp:
- Tính toán Điểm số (Scores):
Gating Networkchứa một ma trận trọng sốWg. Nó thực hiện một phép nhân ma trận đơn giản giữa vector đầu vàoxvà ma trậnWgđể tạo ra một vectorlogits. Vector này có số chiều bằng với số lượngexpert. Mỗi phần tử tronglogitsđại diện cho "điểm số thô" màgatedành cho mỗiexpert.Scores = x • Wg - Áp dụng Softmax: Để biến các điểm số thô thành một thứ gì đó có ý nghĩa hơn (như xác suất), chúng ta áp dụng hàm
Softmax. Kết quả là một vectorG(x), trong đó mỗi phần tửG(x)inằm trong khoảng (0, 1) và tổng của tất cả các phần tử bằng 1.G(x)icó thể được hiểu là "mức độ tự tin" củagaterằngexpertthứilà phù hợp để xử lýtokenx.G(x) = Softmax(Scores) - Top-k Routing: Đây là một cải tiến quan trọng so với ý tưởng ban đầu. Thay vì chỉ chọn một
expertcó điểm cao nhất (Top-1), các mô hình hiện đại thường chọn rakexpertscó điểm cao nhất. Ví dụ, Mixtral 8x7B sử dụngk=2. Tại sao lại như vậy? Bởi vì một vấn đề phức tạp có thể cần sự kết hợp của nhiều lĩnh vực chuyên môn. Ví dụ, khi xử lý câu "Write a Python function to calculate Fibonacci sequence recursively", mô hình có thể cần kích hoạt cảexpertvề "lập trình Python" vàexpertvề "lý thuyết thuật toán". - Tổng hợp kết quả theo trọng số: Đầu ra cuối cùng của MoE layer không phải là đầu ra của một
expertduy nhất. Nó là tổng của các đầu ra từkexpertsđược chọn, nhưng được "trọng số hóa" bởi chính điểmsoftmaxmàGating Networkđã tính.Output(x) = Σ (G(x)i * Ei(x))(trong đóilà chỉ số của cácexperttrong top-k, vàEi(x)là đầu ra củaexpertthứikhi xử lýx).
Điều này có nghĩa là, expert nào có điểm softmax cao hơn sẽ có tiếng nói lớn hơn trong kết quả cuối cùng.
4. Kết luận
Mixture-of-Experts không chỉ là một bước tiến về mặt kiến trúc, mà còn là giải pháp nền tảng giúp AI vượt qua giới hạn về hiệu năng, chi phí và khả năng mở rộng. Hy vọng qua bài viết này, bạn đã nắm được những kiến thức nền tảng về MoE và tự tin hơn khi tiếp cận các mô hình hiện đại dựa trên kiến trúc này