Thuật toán là gì ? Những thuật toán phổ biến Developer nên biết
12 Oct, 2024
Vo Chi Truong
AuthorThuật toán là một chuỗi các bước tính toán để biến đầu vào (input) thành đầu ra (output).

Mục Lục
Thuật toán (hay Algorithm) - cụm từ mà chúng ta nghe thấy rất nhiều trong thế giới công nghệ hiện nay. Từ việc tìm kiếm trên Google, tối ưu quảng cáo, đến điều khiển xe tự lái, thuật toán đang hiện diện ở khắp nơi, chi phối mọi hoạt động trong cuộc sống số.
Nhưng bạn có bao giờ tự hỏi, thực chất thuật toán là gì? Làm thế nào mà những dòng mã khô khan lại có thể giải quyết những bài toán phức tạp, mang lại hiệu suất tối ưu cho các hệ thống khổng lồ? Bài viết này sẽ khám phá bí mật ẩn sau các thuật toán – những "bộ não" thầm lặng của công nghệ hiện đại, và tại sao chúng lại có tầm quan trọng đến vậy.
1. Thuật toán là gì?
Theo cuốn sách Introduction to Algorithms được xuất bản bởi The MIT Press, thuật toán (Algorithms) được định nghĩa như sau: Thuật toán là một chuỗi các bước tính toán để biến đầu vào (input) thành đầu ra (output).

Ví dụ: Mô phỏng các bước mà thuật toán sẽ thực hiện với món trứng chiên:
- Bước 1: Chuẩn bị nguyên liệu (Input)
Input: Trứng, hành lá, gia vị (muối, tiêu), dầu ăn.
Xử lý: Đập trứng vào bát, thêm hành lá, muối, tiêu, đánh đều.
- Bước 2: Đun nóng dầu (Chuẩn bị môi trường)
Xử lý: Cho dầu ăn vào chảo, đun nóng ở lửa vừa.
- Bước 3: Đổ trứng vào chảo (Thực hiện quá trình chính)
Xử lý: Đổ hỗn hợp trứng đã đánh vào chảo. Dàn đều trứng khắp bề mặt chảo.
- Bước 4: Chiên và lật trứng (Xử lý tiếp theo)
Xử lý: Chiên mặt dưới cho đến khi chín vàng, sau đó lật trứng để chiên mặt còn lại.
- Bước 5: Hoàn thành món ăn (Output)
Output: Khi trứng chín đều, bạn lấy trứng ra và có món trứng chiên hoàn chỉnh.
2. Vì sao Thuật toán lại quan trọng?
2.1 Thuật toán được dùng để làm gì?
Thuật toán đóng vai trò quan trọng trong nhiều công nghệ và dịch vụ mà chúng ta sử dụng hàng ngày, với các ứng dụng đa dạng:
- Điều hướng GPS: Thuật toán phân tích dữ liệu thời gian thực về giao thông, giúp tìm đường nhanh nhất.
- Mua sắm trực tuyến: Thuật toán phân tích lịch sử duyệt web và mua hàng để gợi ý sản phẩm phù hợp, cá nhân hóa trải nghiệm.
- Ngân hàng: Thuật toán giám sát giao dịch để phát hiện và ngăn chặn gian lận.
- Mạng xã hội: Thuật toán phân tích tương tác và sở thích để tạo nguồn cấp dữ liệu phù hợp, thu hút người dùng.
- Công cụ tìm kiếm: Thuật toán sàng lọc thông tin để trả về kết quả phù hợp nhất.
Thuật toán là nền tảng của công nghệ hiện đại, giúp cuộc sống chúng ta trở nên dễ dàng, an toàn và hiệu quả hơn trong nhiều lĩnh vực.
2.2 Lợi ích của việc sử dụng thuật toán
- Tự động hóa và hiệu quả: Thuật toán giúp tự động hóa các tác vụ lặp đi lặp lại, giúp tiết kiệm thời gian và công sức. Điều này đặc biệt hữu ích trong các lĩnh vực như sản xuất, phân tích dữ liệu, và xử lý hình ảnh.
- Tối ưu hóa hiệu suất: Các thuật toán được thiết kế để tối ưu hóa hiệu suất của hệ thống, giúp tìm ra giải pháp tốt nhất trong thời gian ngắn nhất có thể. Ví dụ, thuật toán tìm kiếm và sắp xếp giúp tìm kiếm dữ liệu nhanh hơn, thuật toán tối ưu hóa giúp giảm thiểu chi phí hoặc tối đa hóa lợi nhuận.
- Giải quyết vấn đề phức tạp: Thuật toán có thể giúp giải quyết các bài toán phức tạp mà con người khó có thể giải quyết bằng tay, như các vấn đề trong lĩnh vực trí tuệ nhân tạo, học máy, và phân tích dữ liệu lớn.

- Tính nhất quán và chính xác: Khi được thực hiện đúng, thuật toán đảm bảo rằng quá trình giải quyết vấn đề diễn ra một cách chính xác và nhất quán, hạn chế rủi ro từ các sai sót do con người gây ra.
- Khả năng mở rộng: Thuật toán giúp xử lý và quản lý một lượng lớn dữ liệu và tác vụ, điều này giúp các hệ thống công nghệ thông tin có thể mở rộng quy mô một cách dễ dàng.
- Dự đoán và ra quyết định: Trong lĩnh vực như dự báo thời tiết, kinh doanh và y tế, thuật toán giúp phân tích dữ liệu lịch sử và hiện tại để đưa ra dự đoán và hỗ trợ ra quyết định chính xác hơn.
Ví dụ: Tìm kiếm phần tử có sử dụng thuật toán (Thuật toán tìm kiếm nhị phân): Giả sử bạn cần tìm một số trong một danh sách đã được sắp xếp. Thuật toán tìm kiếm nhị phân chia nhỏ danh sách ra theo từng bước, giúp giảm số lần so sánh cần thiết. Với một danh sách có 1.000.000 phần tử, thuật toán này chỉ cần khoảng 20 bước để tìm ra kết quả.
- Lợi ích: Tìm kiếm rất nhanh, hiệu quả, kể cả với dữ liệu lớn.
Nếu bạn không sử dụng thuật toán và tìm kiếm theo cách thông thường (tìm kiếm tuyến tính), bạn sẽ phải duyệt qua từng phần tử một, có thể mất đến 1.000.000 bước trong trường hợp tệ nhất.
- Kết quả: Tốn thời gian và tài nguyên đáng kể, hiệu suất thấp khi đối diện với lượng dữ liệu lớn. Đoạn code sau sử dụng thuật toán tìm kiếm nhị phân:
import time
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# Danh sách đã được sắp xếp
arr = list(range(1, 10000001)) # 10 triệu phần tử
target = 9999999
# Đo thời gian thực hiện thuật toán tìm kiếm nhị phân
start_time = time.time()
result = binary_search(arr, target)
end_time = time.time()
print(f"Tìm thấy phần tử tại chỉ số: {result}")
print(f"Thời gian chạy của thuật toán tìm kiếm nhị phân: {end_time - start_time} giây")
Đoạn code sau không sử dụng thuật toán (tìm kiếm bằng cách duyệt qua từng phần tử một cho đến khi tìm thấy kết quả:
import time
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
# Danh sách đã được sắp xếp
arr = list(range(1, 10000001)) # 10 triệu phần tử
target = 9999999
# Đo thời gian thực hiện tìm kiếm tuyến tính
start_time = time.time()
result = linear_search(arr, target)
end_time = time.time()
print(f"Tìm thấy phần tử tại chỉ số: {result}")
print(f"Thời gian chạy của tìm kiếm tuyến tính: {end_time - start_time} giây")
Các bạn có thể chạy thử các đoạn mã trên ở Online Python. Kết quả cho thấy khi sử dụng thuật toán nhị phân thì tiết kiệm nhiều thời gian so với việc không sử dụng thuật toán.
3. Tiêu chí đánh giá hiệu năng của thuật toán
- Độ phức tạp thời gian (Time Complexity):
Đây là chỉ số đo lường thời gian mà thuật toán cần để hoàn thành công việc dựa trên kích thước đầu vào. Độ phức tạp thường được biểu diễn dưới dạng Big-O (O(n), O(log n), O(n²),...). Một thuật toán có thời gian chạy ngắn sẽ được đánh giá cao. - Độ phức tạp không gian (Space Complexity):
Độ phức tạp không gian đo lường lượng bộ nhớ cần sử dụng khi thực thi thuật toán. Thuật toán hiệu quả sẽ tối ưu về cả thời gian và bộ nhớ. - Độ chính xác (Accuracy):
Đối với các thuật toán học máy, thuật toán tìm kiếm hoặc sắp xếp, độ chính xác của kết quả đầu ra là một yếu tố quan trọng để đánh giá hiệu năng. - Khả năng mở rộng (Scalability):
Một thuật toán tốt cần có khả năng xử lý hiệu quả khi kích thước dữ liệu đầu vào tăng lên. Tính mở rộng giúp thuật toán hoạt động tốt trên các hệ thống lớn. - Tính ổn định (Stability):
Thuật toán ổn định sẽ giữ nguyên thứ tự của các phần tử bằng nhau sau khi sắp xếp. Điều này đặc biệt quan trọng trong các thuật toán sắp xếp.

- Tính dễ hiểu và dễ bảo trì (Understandability and Maintainability):
Một thuật toán tốt không chỉ cần hiệu quả mà còn phải dễ hiểu và dễ bảo trì, giúp người phát triển dễ dàng sửa đổi hoặc nâng cấp khi cần thiết. - Tính khả dụng (Usability):
Đây là tiêu chí đánh giá liệu thuật toán có thể được áp dụng hiệu quả trong các bài toán thực tế không. Một thuật toán có thể rất nhanh và chính xác nhưng nếu không khả thi trong thực tế thì vẫn khó được sử dụng rộng rãi. - Tính xác định (Determinism):
Một thuật toán xác định sẽ cho cùng một kết quả với cùng một đầu vào. Điều này rất quan trọng trong các hệ thống yêu cầu tính nhất quán. - Khả năng xử lý đồng thời (Concurrency):
Với các hệ thống hiện đại, việc đánh giá liệu thuật toán có khả năng xử lý đa luồng hoặc xử lý đồng thời hay không cũng là một tiêu chí quan trọng. - Tính bền vững (Robustness):
Tính bền vững của một thuật toán đo lường khả năng của nó trong việc xử lý các trường hợp bất thường hoặc dữ liệu không hợp lệ mà không bị lỗi nghiêm trọng.
4. Những thuật toán phổ biến nhất hiện nay
4.1 Tìm kiếm nhị phân
Thuật toán Binary Search hoạt động bằng cách kiểm tra giá trị ở giữa mảng. Nếu giá trị mục tiêu thấp hơn, giá trị tiếp theo cần kiểm tra sẽ nằm ở giữa nửa bên trái của mảng. Cách tìm kiếm này có nghĩa là vùng tìm kiếm luôn bằng một nửa vùng tìm kiếm trước đó và đây là lý do tại sao thuật toán Binary Search lại nhanh như vậy.

4.2 Sắp xếp
- Selection Sort: Thuật toán sẽ xem xét lại mảng nhiều lần, di chuyển các giá trị thấp nhất tiếp theo lên phía trước, cho đến khi mảng được sắp xếp.
- Bubble Sort: Thuật toán sẽ duyệt qua mảng từng giá trị một. So sánh giá trị hiện tại với giá trị tiếp theo. Nếu giá trị hiện tại cao hơn giá trị tiếp theo thì hoán đổi các giá trị sao cho giá trị cao nhất đứng ở cuối cùng.
- Insertion Sort: Thuật toán này lấy một giá trị tại một thời điểm từ phần chưa được sắp xếp của mảng và đặt nó vào đúng vị trí trong phần đã được sắp xếp của mảng, cho đến khi mảng được sắp xếp.
- Quick Sort: Thuật toán Quicksort lấy một mảng giá trị, chọn một trong các giá trị làm phần tử 'trục' và di chuyển các giá trị khác sao cho các giá trị thấp hơn nằm ở bên trái phần tử trục và các giá trị cao hơn nằm ở bên phải phần tử trục. Thuật toán Quicksort thực hiện cùng một thao tác đệ quy trên các mảng con ở phía bên trái và bên phải của phần tử trục. Điều này tiếp tục cho đến khi mảng được sắp xếp.
- Merge Sort: Thuật toán bắt đầu bằng việc chia mảng thành các phần nhỏ hơn cho đến khi một mảng con chỉ bao gồm một phần tử. Thuật toán hợp nhất các phần nhỏ của mảng lại với nhau bằng cách đặt các giá trị thấp nhất lên trước, tạo thành một mảng đã được sắp xếp.
4.4 Huffman Coding
Huffman Coding là một thuật toán nén dữ liệu không mất mát (lossless compression), Thuật toán này được sử dụng để mã hóa các ký tự dựa trên tần suất xuất hiện của chúng trong dữ liệu gốc.
Những ký tự xuất hiện nhiều hơn sẽ được mã hóa bằng chuỗi bit ngắn hơn, trong khi những ký tự ít xuất hiện sẽ được mã hóa bằng chuỗi bit dài hơn. Điều này giúp tối ưu hóa việc nén dữ liệu, tiết kiệm không gian lưu trữ mà vẫn có thể tái tạo lại dữ liệu gốc mà không mất thông tin.
Huffman Coding được xem là một trong những thuật toán nén phổ biến nhất trong các hệ thống truyền thông và nén dữ liệu như các định dạng file hình ảnh (JPEG), âm thanh (MP3), và video.
Cách thức hoạt động của Huffman Coding:
- Đếm tần suất xuất hiện của từng dữ liệu.
- Xây dựng một cây nhị phân , bắt đầu với các nút có số lượng thấp nhất. Nút cha mới có số lượng kết hợp của các nút con của nó.
- Cạnh từ cha mẹ nhận được '0' cho con bên trái và '1' cho cạnh từ con bên phải.
- Trong cây nhị phân đã hoàn thiện, hãy theo dõi các cạnh từ nút gốc, thêm '0' hoặc '1' cho mỗi nhánh để tìm mã Huffman mới cho từng phần dữ liệu.
- Tạo mã Huffman bằng cách chuyển đổi dữ liệu từng phần thành mã nhị phân bằng cách sử dụng cây nhị phân.
4.5 Breadth First Search
Breadth First Search (Tìm kiếm theo chiều rộng) sẽ duyệt tất cả các đỉnh kề nhau của một đỉnh trước khi duyệt các đỉnh lân cận của các đỉnh kề nhau. Điều này có nghĩa là các đỉnh có cùng khoảng cách từ đỉnh bắt đầu sẽ được duyệt trước khi duyệt các đỉnh xa hơn so với đỉnh bắt đầu.
4.6 Depth First Search
Depth First Search (Tìm kiếm theo chiều sâu) được cho là "sâu" vì nó duyệt một đỉnh, sau đó là một đỉnh liền kề, rồi đến đỉnh liền kề của đỉnh đó, v.v. và theo cách này, khoảng cách từ đỉnh bắt đầu tăng lên sau mỗi lần lặp đệ quy.
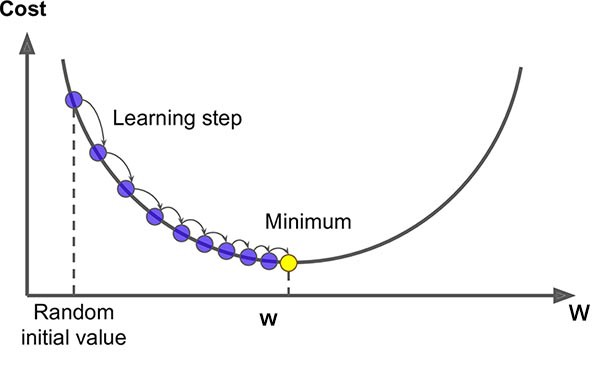
4.7 Gradient Descent
Gradient Descent là một phương pháp giúp tìm ra giá trị tối ưu cho các tham số trong mô hình máy học. Hãy tưởng tượng bạn đang đứng trên đỉnh một ngọn đồi và muốn xuống dưới đáy. Bạn không thể nhìn thấy toàn bộ khu vực xung quanh, chỉ có thể nhìn xuống chân đồi.
Cách hoạt động:
- Bạn nhìn xung quanh để xác định hướng dốc nhất (nghĩa là nơi có độ dốc lớn nhất), và bạn đi xuống theo hướng đó.
- Mỗi lần đi, bạn chỉ đi một khoảng nhất định (gọi là tốc độ học - learning rate), rồi lại nhìn lại để xác định hướng đi tiếp.
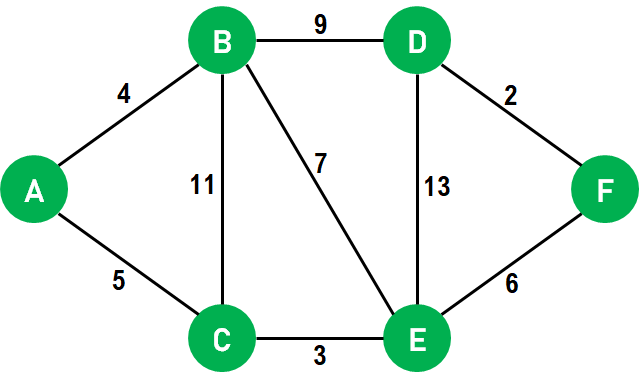
4.8 Dijkstra
Thuật toán Dijkstra là một thuật toán nổi tiếng dùng để tìm đường đi ngắn nhất từ một điểm xuất phát đến các điểm khác trong đồ thị có trọng số dương, được phát minh bởi nhà toán học người Hà Lan Edsger Dijkstra vào năm 1956.
Điểm đặc biệt của thuật toán Dijkstra là hoạt động theo nguyên tắc "tham lam" (greedy algorithm), nghĩa là sẽ luôn chọn con đường tốt nhất ở hiện tại mà không cần biết đến những quyết định trong tương lai. Nhờ nguyên tắc này, thuật toán Dijkstra giúp giảm thời gian xử lý và tìm ra đường đi ngắn nhất cách hiệu quả.
5. Kết luận
Trong bài viết này, chúng ta đã cùng nhau tìm hiểu về khái niệm, phân loại, và tầm quan trọng của chúng trong cuộc sống hàng ngày. Thuật toán không chỉ đơn thuần là những dòng mã mà còn là những công cụ mạnh mẽ giúp chúng ta giải quyết những vấn đề phức tạp, tối ưu hóa quy trình và nâng cao hiệu suất.
Bài viết liên quan: