Cấu trúc dữ liệu và Giải thuật là gì ? (Data Structures & Algorithms)
22 Aug, 2024
Vo Chi Truong
AuthorCấu trúc dữ liệu giúp lưu trữ và truy cập dữ liệu hiệu quả. Giải thuật là tập hợp các bước/quy tắc để giải quyết vấn đề hoặc tối ưu hóa dữ liệu

Mục Lục
Cấu trúc dữ liệu và giải thuật (Data Structure and Algorithm) là nền tảng quan trọng trong lập trình, giúp quản lý và xử lý dữ liệu hiệu quả. Cấu trúc dữ liệu giúp lưu trữ và truy cập dữ liệu nhanh chóng, trong khi giải thuật là một tập hợp các bước hoặc quy tắc được thiết kế để giải quyết vấn đề hoặc tối ưu hóa dữ liệu. Hiểu rõ về DSA sẽ giúp bạn tối ưu hóa hiệu suất chương trình và giải quyết các vấn đề phức tạp một cách có hệ thống.
1. Cấu trúc dữ liệu và giải thuật là gì ?
1.1 Cấu trúc dữ liệu là gì ?
Cấu trúc dữ liệu là một cách tổ chức và lưu trữ dữ liệu trong máy tính sao cho có thể truy cập và sửa đổi một cách hiệu quả.
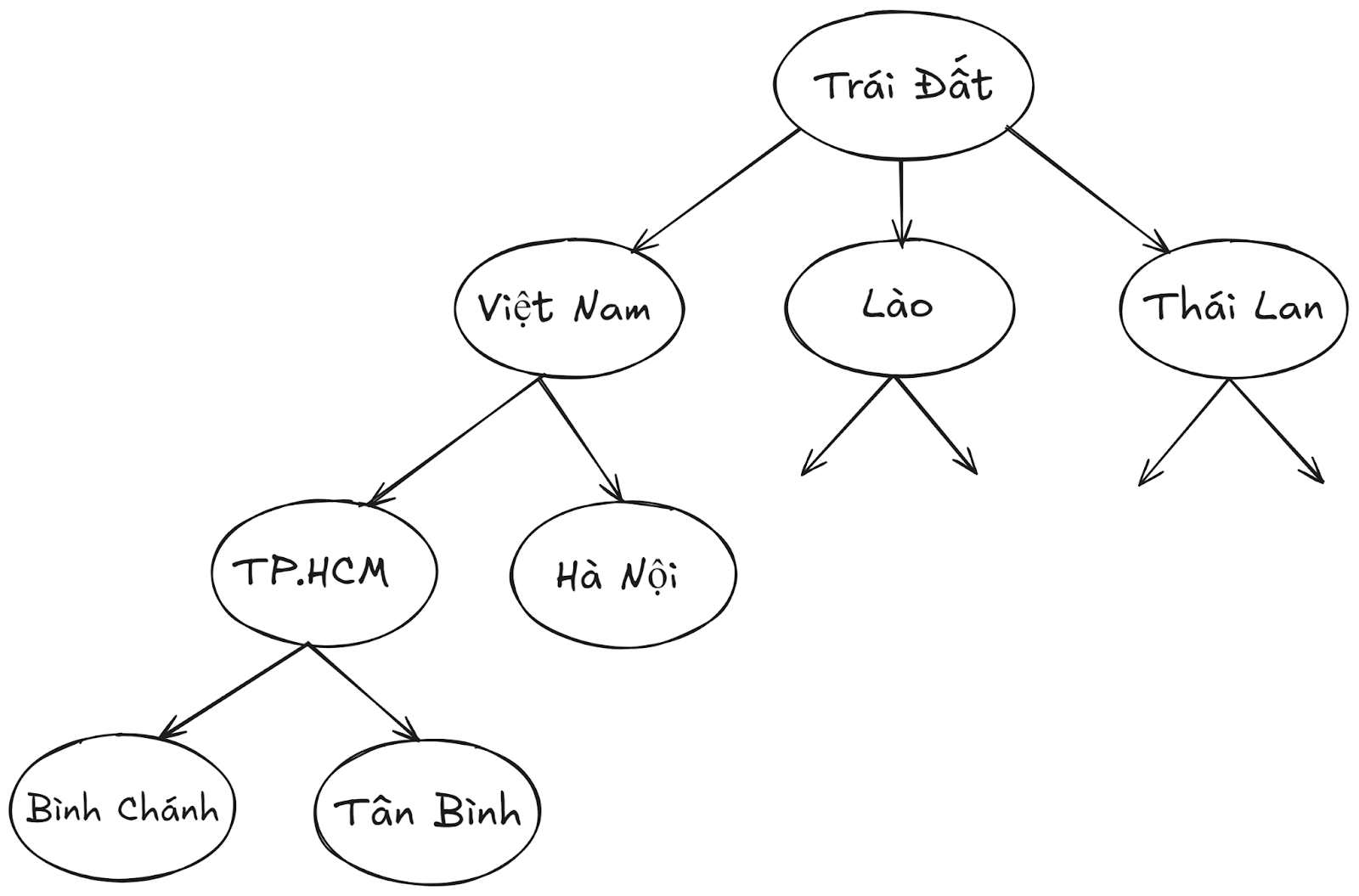
Các đặc trưng trong cấu trúc dữ liệu bao gồm:
- Tính tuyến tính hoặc phi tuyến tính: Đặc tính này xác định xem các phần tử dữ liệu có được sắp xếp theo một thứ tự nhất định hay không. Cấu trúc dữ liệu tuyến tính là loại cấu trúc trong đó các phần tử được tổ chức theo một trình tự cụ thể (Mảng, Danh sách liên kết), trong khi cấu trúc phi tuyến tính thì không có thứ tự cố định cho các phần tử (Cây, Đồ thị).
- Tính đồng nhất hoặc không đồng nhất: Đặc tính này mô tả liệu tất cả các phần tử dữ liệu trong một kho lưu trữ nhất định có cùng loại hay không. Trong cấu trúc dữ liệu đồng nhất, tất cả các phần tử đều có cùng kiểu dữ liệu và thuộc tính, còn trong cấu trúc không đồng nhất thì có thể chứa các kiểu dữ liệu và thuộc tính khác nhau.
- Tính tĩnh hoặc động: Đặc tính này mô tả cách các cấu trúc dữ liệu được quản lý. Cấu trúc dữ liệu tĩnh có kích thước, cấu trúc và vị trí bộ nhớ cố định tại thời điểm biên dịch, không thay đổi trong quá trình thực thi. Ngược lại, cấu trúc dữ liệu động có kích thước, cấu trúc và vị trí bộ nhớ có thể thay đổi theo thời gian và tùy thuộc vào cách sử dụng trong quá trình thực thi.
1.2 Giải thuật là gì ?
Giải thuật (hay thuật toán) là một tập hợp các bước hướng dẫn cụ thể, rõ ràng và có trình tự logic để giải quyết một vấn đề hoặc thực hiện một nhiệm vụ nào đó. Giải thuật có thể được áp dụng trong nhiều lĩnh vực khác nhau, từ toán học, khoa học máy tính đến cuộc sống hàng ngày.
Ví dụ: Giả sử bạn cần giải quyết vấn đề biến gạo thành cơm để ăn (hay nấu cơm) thì cần phải thực hiện các bước sau đây:

Các đặc trưng trong thuật toán bao gồm:
- Tính xác định: Giải thuật phải rõ ràng và không mơ hồ. Mỗi giai đoạn (hay mỗi bước) cần được định nghĩa một cách chính xác và chỉ thực hiện một nhiệm vụ cụ thể.
- Dữ liệu đầu vào xác định: Một giải thuật có thể có không hoặc nhiều dữ liệu đầu vào đã được xác định trước.
- Kết quả đầu ra: Một giải thuật cần phải có một hoặc nhiều dữ liệu đầu ra được xác định rõ ràng và phù hợp với kết quả mong đợi.
- Tính dừng: Giải thuật phải kết thúc sau một số bước hữu hạn.
- Tính hiệu quả: Giải thuật cần có khả năng thực hiện với các tài nguyên sẵn có, tức là có thể giải quyết vấn đề hiệu quả trong các điều kiện thời gian và tài nguyên cho phép.
- Tính phổ biến: Giải thuật có tính phổ biến nếu có thể áp dụng để giải quyết một lớp các vấn đề tương tự.
- Độc lập: Giải thuật nên bao gồm các chỉ thị không phụ thuộc vào bất kỳ đoạn mã lập trình cụ thể nào.
2. Tầm quan trọng của Cấu trúc dữ liệu và giải thuật
Để biết được tầm quan trọng của cấu trúc dữ liệu và giải thuật, mình sẽ trình bày một ví dụ:
Thư viện có hàng trăm ngàn cuốn sách với nhiều thể loại, tác giả và năm xuất bản khác nhau. Người đọc thường xuyên tìm kiếm sách theo các tiêu chí khác nhau (tên sách, tác giả, thể loại, v.v.). Nếu không có một hệ thống tổ chức tốt, việc tìm kiếm một cuốn sách cụ thể có thể mất rất nhiều thời gian và công sức.
Giải pháp:
Cấu trúc dữ liệu:
- Mảng: Lưu trữ thông tin cơ bản của sách (tên, tác giả, thể loại, v.v.) theo thứ tự. Tuy nhiên, việc tìm kiếm trong mảng có thể chậm nếu số lượng sách lớn.
- Danh sách liên kết: Cho phép thêm, xóa sách linh hoạt hơn mảng.
- Cây tìm kiếm nhị phân: Tổ chức sách theo thứ tự, giúp tìm kiếm sách theo tên hoặc tác giả nhanh chóng.
- Bảng băm: Lưu trữ sách theo mã sách, cho phép truy cập nhanh đến thông tin của một cuốn sách cụ thể.
Giải thuật:
- Tìm kiếm tuần tự: Duyệt qua từng cuốn sách trong mảng hoặc danh sách liên kết để tìm kiếm.
- Tìm kiếm nhị phân: Tìm kiếm nhanh trong cây tìm kiếm nhị phân.
- Giải thuật sắp xếp: Sắp xếp sách theo thứ tự tên, tác giả, v.v., giúp việc tìm kiếm dễ dàng hơn.
Kết quả: Nhờ áp dụng cấu trúc dữ liệu và giải thuật phù hợp, thư viện có thể:
- Tổ chức sách hiệu quả: Sách được sắp xếp và lưu trữ một cách có hệ thống, dễ dàng quản lý và bảo trì.
- Tìm kiếm sách nhanh chóng: Người đọc có thể tìm thấy cuốn sách mình cần trong thời gian ngắn.
- Cung cấp dịch vụ tốt hơn: Thư viện có thể đáp ứng nhu cầu của người đọc một cách nhanh chóng và chính xác, nâng cao chất lượng dịch vụ.

Qua ví dụ trên có thể thấy, cấu trúc dữ liệu và giải thuật là vô cùng quan trọng và được sử dụng nhiều trong thực tế. Tóm lại, lý do nên biết cấu trúc dữ liệu và giải thuật là vì:
- Hiệu suất: Lựa chọn cấu trúc dữ liệu và giải thuật phù hợp có thể cải thiện đáng kể hiệu suất của chương trình, đặc biệt khi xử lý lượng dữ liệu lớn. Một giải thuật tốt có thể giảm thời gian chạy từ vài giây xuống vài mili giây (ms), hoặc giảm dung lượng bộ nhớ sử dụng từ vài gigabyte (GB) xuống vài megabyte (MB).
- Khả năng mở rộng: Khi lượng dữ liệu tăng lên, một chương trình được thiết kế tốt với cấu trúc dữ liệu và giải thuật phù hợp sẽ dễ dàng mở rộng để đáp ứng nhu cầu mới. Ngược lại, một chương trình kém hiệu quả có thể trở nên chậm chạp hoặc thậm chí không hoạt động được khi xử lý lượng dữ liệu lớn.
- Chất lượng code: Sử dụng cấu trúc dữ liệu và giải thuật tốt giúp code trở nên rõ ràng, dễ đọc, dễ bảo trì và dễ mở rộng. Điều này đặc biệt quan trọng trong các dự án lớn, nơi nhiều lập trình viên cùng làm việc trên một codebase (hiểu đơn giản là tập hợp toàn bộ tập hợp mã nguồn (source code) được sử dụng để xây dựng một hệ thống phần mềm, ứng dụng hoặc một thành phần phần mềm cụ thể).
- Nền tảng cho các lĩnh vực khác: Cấu trúc dữ liệu và giải thuật là nền tảng cho nhiều lĩnh vực khác trong khoa học máy tính và công nghệ thông tin, như trí tuệ nhân tạo, học máy, xử lý ngôn ngữ tự nhiên, thị giác máy tính,...
- Cơ hội nghề nghiệp: Các công ty công nghệ thường đánh giá cao ứng viên có kiến thức vững chắc về cấu trúc dữ liệu và giải thuật. Nắm vững kiến thức này không chỉ giúp bạn giải quyết các bài toán phỏng vấn mà còn giúp bạn trở thành một lập trình viên giỏi hơn trong công việc thực tế.
3. Các Cấu trúc dữ liệu phổ biến
3.1 Phân loại Cấu trúc dữ liệu
Cấu trúc dữ liệu được phân làm 2 loại chính:
- Cấu trúc dữ liệu tuyến tính (Linear Data Structure)
- Cấu trúc dữ liệu phi tuyến tính (Non-linear Data Structure)

3.1.1 Cấu trúc dữ liệu tuyến tính (Linear Data Structure)
Cấu trúc dữ liệu tuyến tính là cấu trúc trong đó các phần tử dữ liệu được sắp xếp theo thứ tự tuần tự hoặc tuyến tính, và mỗi phần tử được liên kết với phần tử kế tiếp và phần tử trước đó của nó. Các ví dụ về cấu trúc tuyến tính bao gồm mảng, ngăn xếp (stack), hàng đợi (queue), và danh sách liên kết (linked list). Trong cấu trúc dữ liệu Linear, có thể phân chia thành hai loại chính:
Cấu trúc dữ liệu tĩnh (static):
- Đặc điểm: Có kích thước bộ nhớ cố định. Số lượng phần tử được xác định trước và không thể thay đổi trong quá trình chạy chương trình.
- Ưu điểm: Truy cập các phần tử dễ dàng hơn do kích thước cố định.
- Ví dụ: Mảng (Array).
Cấu trúc dữ liệu động (dynamic):
- Đặc điểm: Kích thước không cố định, có thể thay đổi trong thời gian chạy chương trình.
- Ưu điểm: Tối ưu hóa bộ nhớ, linh hoạt trong việc thêm hoặc bớt phần tử.
- Ví dụ: Ngăn xếp (Stack), Hàng đợi (Queue), Danh sách liên kết (Linked list).
Cấu trúc dữ liệu tuyến tính thường được sử dụng trong các tình huống mà các phần tử cần được xếp theo thứ tự nhất định và có thể được truy cập bằng chỉ số hoặc con trỏ. Ví dụ, lưu trữ một danh sách sinh viên và truy cập bằng số thứ tự. Cấu trúc dữ liệu Linear cũng hiệu quả cho các thao tác sắp xếp, tìm kiếm, thêm hoặc xóa phần tử.
3.1.2 Cấu trúc dữ liệu phi tuyến tính (Non-linear Data Structure)
Cấu trúc dữ liệu phi tuyến tính không có cấu trúc phân cấp rõ ràng, nghĩa là các phần tử có thể có nhiều phần tử con và/hoặc cha. Các ví dụ về cấu trúc dữ liệu phi tuyến tính bao gồm cây (Tree) và đồ thị (Graph).
- Cây (Tree): Được sử dụng để lưu trữ dữ liệu có thứ tự như các cây phân nhánh.
- Đồ thị (Graph): Sử dụng trong các thuật toán tìm kiếm, định tuyến, và tối ưu hóa mạng.
Cấu trúc dữ liệu phi tuyến tính thường được áp dụng khi các đối tượng trong chương trình có mối quan hệ phức tạp hoặc cấu trúc không đều. Điều này giúp cho việc xử lý các bài toán đòi hỏi quản lý dữ liệu phức tạp và không tuần tự.
3.2 Cách chọn cấu trúc dữ liệu phù hợp
Việc chọn cấu trúc dữ liệu phù hợp phụ thuộc vào bài toán cụ thể và các thao tác bạn cần thực hiện trên dữ liệu. Dưới đây là một số hướng dẫn chọn cấu trúc dữ liệu dựa trên nhu cầu và đặc điểm của bài toán:
1. Mảng (Array):
- Sử dụng khi: Cần truy cập nhanh vào các phần tử bằng chỉ số.
- Ưu điểm: Truy cập phần tử theo chỉ số có độ phức tạp O(1).
- Nhược điểm: Kích thước cố định, khó thay đổi kích thước và thực hiện các thao tác chèn hoặc xóa phần tử.
2. Danh sách liên kết (Linked List):
- Sử dụng khi: Cần chèn và xóa phần tử thường xuyên.
- Ưu điểm: Dễ dàng thay đổi kích thước, chèn và xóa phần tử có độ phức tạp O(1) nếu bạn có con trỏ đến vị trí cần thay đổi.
- Nhược điểm: Truy cập phần tử theo chỉ số có độ phức tạp O(n), cần nhiều bộ nhớ hơn do lưu trữ con trỏ.
3. Ngăn xếp (Stack):
- Sử dụng khi: Cần xử lý các bài toán liên quan đến lịch sử (undo/redo), hoặc các bài toán kiểu "LIFO" (Last In, First Out).
- Ưu điểm: Thực hiện các thao tác thêm và xóa phần tử (push và pop) có độ phức tạp O(1).
- Nhược điểm: Chỉ có thể truy cập phần tử ở đỉnh của ngăn xếp, không thể truy cập các phần tử khác dễ dàng.
4. Hàng đợi (Queue):
- Sử dụng khi: Cần xử lý các bài toán mô phỏng hàng đợi, hoặc các bài toán kiểu "FIFO" (First In, First Out).
- Ưu điểm: Thực hiện các thao tác thêm phần tử vào cuối hàng đợi (enqueue) và xóa phần tử từ đầu hàng đợi (dequeue) có độ phức tạp O(1).
- Nhược điểm: Không thể truy cập phần tử ở giữa hàng đợi dễ dàng.
5. Cây (Tree):
- Sử dụng khi: Cần biểu diễn các mối quan hệ phân cấp, như tổ chức dữ liệu theo cấu trúc phân cấp hoặc cây quyết định.
- Ưu điểm: Có thể đại diện cho dữ liệu với cấu trúc phân cấp rõ ràng và hiệu quả trong các thao tác tìm kiếm, chèn, xóa.
- Nhược điểm: Cần quản lý cấu trúc cây và có thể cần nhiều bộ nhớ hơn.
6. Đồ thị (Graph):
- Sử dụng khi: Cần biểu diễn các mối quan hệ phức tạp, như mạng lưới, các mối quan hệ giữa các đối tượng, hoặc các bài toán định tuyến.
- Ưu điểm: Linh hoạt trong việc biểu diễn các mối quan hệ đa dạng và có thể sử dụng cho các thuật toán tìm kiếm và tối ưu hóa.
- Nhược điểm: Có thể phức tạp trong việc quản lý và có thể tiêu tốn nhiều bộ nhớ và thời gian tính toán cho các thao tác trên đồ thị.
Vậy cấu trúc dữ liệu (Data Structure) và kiểu dữ liệu (Data Type) có gì khác nhau ? Kiểu dữ liệu xác định các loại dữ liệu có thể được sử dụng trong chương trình thì cấu trúc dữ liệu xác định các dữ liệu được tổ chức và quản lý trong bộ nhớ. Cụ thể có những khác biệt sau:
4. Các giải thuật phổ biến
4.1 Các giải thuật tìm kiếm
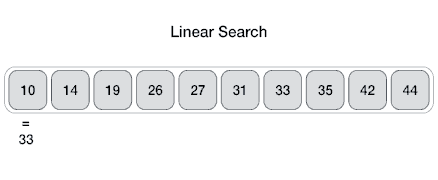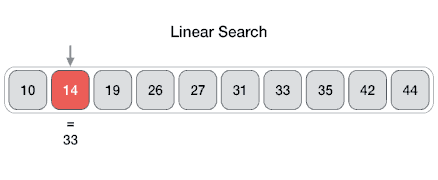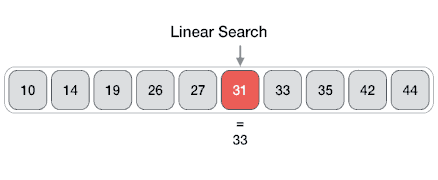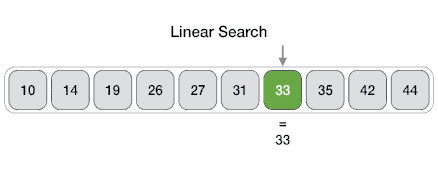
- Tìm kiếm tuần tự (Linear Search)
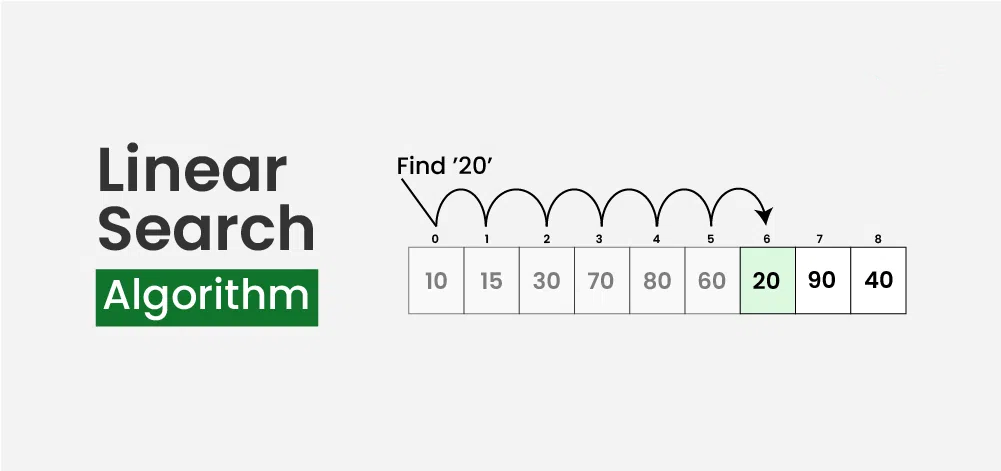
Thuật toán tìm kiếm tuyến tính được định nghĩa là thuật toán tìm kiếm tuần tự bắt đầu từ đầu và duyệt qua từng phần tử của danh sách cho đến khi tìm thấy phần tử mong muốn; nếu không, quá trình tìm kiếm sẽ tiếp tục cho đến hết dữ liệu.
Ví dụ:
- Tìm kiếm nhị phân (Binary Search)
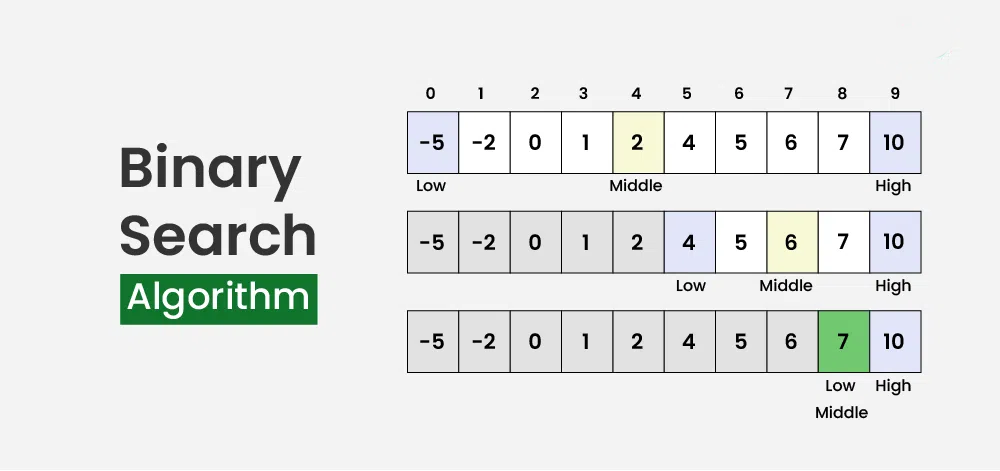
Tìm kiếm nhị phân là một tìm kiếm thuật toán được sử dụng để tìm vị trí của mục tiêu giá trị trong một mảng được sắp xếp . Nó hoạt động bằng cách liên tục chia khoảng thời gian tìm kiếm đôi khi tìm thấy mục tiêu giá trị hoặc khoảng thời gian trống. Khoảng thời gian tìm kiếm giảm đi một nửa bằng cách so sánh mục tiêu tử với giá trị ở giữa không tìm kiếm.
Ví dụ:

4.2 Các giải thuật sắp xếp
- Sắp xếp nổi bọt (Bubble Sort)
Sắp xếp nổi bọt là thuật toán sắp xếp đơn giản nhất hoạt động bằng cách liên tục thay đổi các phần tử liền kề nếu chúng sai thứ tự. Thuật toán này không phù hợp với các dữ liệu lớn vì mức độ phức tạp về thời gian trung bình và trường hợp xấu nhất của nó khá cao.
Ví dụ:
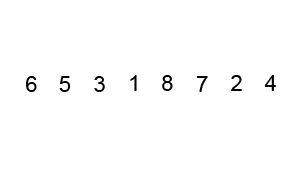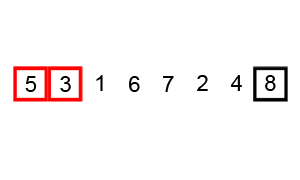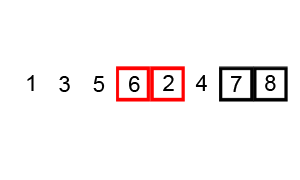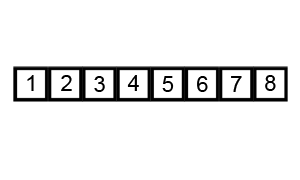
- Sắp xếp chèn (Insertion Sort)
Sắp xếp chèn là một thuật toán sắp xếp đơn giản hoạt động bằng cách lặp đi lặp lại việc chèn từng phần tử của danh sách chưa được sắp xếp vào đúng vị trí của nó trong phần được sắp xếp của danh sách. Đây là một thuật toán sắp xếp ổn định , nghĩa là các phần tử có giá trị bằng nhau sẽ duy trì thứ tự tương đối của chúng trong kết quả được sắp xếp.
Ví dụ:
- Sắp xếp nhanh (Quick Sort)
Sắp xếp nhanh là một thuật toán sắp xếp dựa trên thuật toán chia để trị (Divide and Conquer), chọn một phần tử làm trục và phân chia mảng đã cho xung quanh trục đã chọn bằng cách đặt trục vào đúng vị trí của nó trong mảng đã sắp xếp.
Ví dụ:
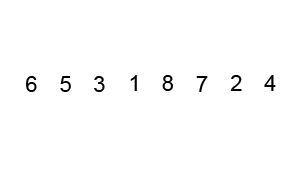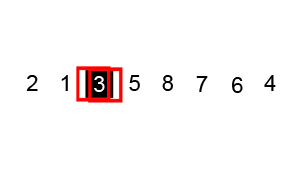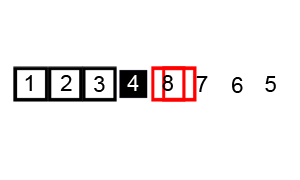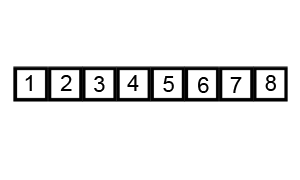
- Sắp xếp trộn (Merge Sort)
Sắp xếp trộn là thuật toán sắp xếp theo phương pháp chia để trị (Divide and Conquer). Thuật toán này hoạt động bằng cách đệ quy chia mảng đầu thành các mảng con nhỏ hơn và sắp xếp các mảng con đó sau đó chúng hợp nhất lại với nhau để thu được mảng được sắp xếp.
Ví dụ:
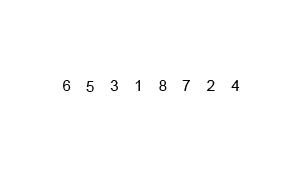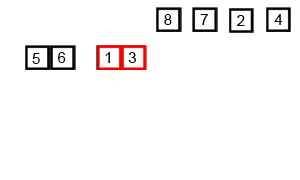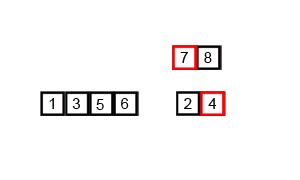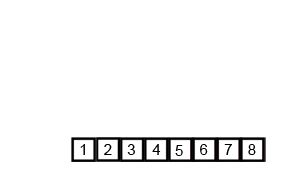
4.3 Đệ quy
Trong khoa học máy tính, khái niệm đệ quy là một phương pháp giải toán, trong đó, lời giải của bài toán phụ thuộc vào một trường hợp nhỏ hơn của cùng một bài toán đó.
Đệ quy có ưu điểm là thuận lợi cho việc biểu diễn bài toán, đồng thời làm gọn chương trình. Tuy nhiên cũng có nhược điểm, đó là không tối ưu về mặt thời gian (so với sử dụng vòng lặp), gây tốn bộ nhớ và có thể tràn stack nếu không kiểm soát tốt độ sâu của đệ quy.
Các loại đệ quy thường gặp:
- Đệ quy tuyến tính (Linear Recursion)
- Đệ quy nhị phân (Binary Recursion)
- Đệ quy lồng (Nested Recursion)
- Đệ quy hỗ tương (Mutual Recursion)
- Quay lui (Backtracking)
Để tìm hiểu kỹ hơn về các loại đệ quy trên, các bạn có thể đọc qua bài viết “Đệ Quy là gì? Có bao nhiêu loại Đệ Quy cơ bản?” của 200Lab nhé !
4.4 Quy hoạch động
Quy hoạch động (dynamic programming) là một kỹ thuật trong toán học và khoa học máy tính giúp giải quyết các vấn đề phức tạp bằng cách chia nhỏ chúng thành các bài toán con đơn giản hơn. Phương pháp này giải quyết mỗi bài toán con một lần và lưu trữ kết quả, giúp tránh các phép tính lặp lại không cần thiết và tăng hiệu quả giải quyết vấn đề.

4.4.1 Nguyên lý hoạt động của quy hoạch động
- Chia bài toán thành các bài toán con nhỏ hơn: Bài toán ban đầu được chia thành các bài toán con nhỏ hơn mà mỗi bài toán con là một phần của bài toán lớn hơn. Các bài toán con này thường có tính chất lặp lại.
- Lưu trữ kết quả của các bài toán con: Để tránh việc tính toán lặp lại các bài toán con nhiều lần, kết quả của chúng được lưu trữ trong một bảng (thường là mảng hoặc ma trận).
- Sử dụng lại kết quả đã lưu: Khi cần kết quả của một bài toán con nào đó, chương trình sẽ kiểm tra bảng lưu trữ để xem kết quả đã được tính toán trước đó chưa. Nếu đã có, nó sẽ sử dụng lại kết quả đó thay vì tính toán lại từ đầu.
Phương pháp này giúp tăng hiệu quả bằng cách loại bỏ các phép tính dư thừa và đảm bảo rằng mỗi bài toán con chỉ được giải một lần. Điều này dẫn đến giải pháp tối ưu và hiệu quả hơn cho nhiều loại bài toán phức tạp.
4.4.2 Ưu điểm và nhược điểm của quy hoạch động
Ưu điểm:
- Giảm thời gian tính toán: Quy hoạch động giúp giảm thiểu số lượng phép tính cần thực hiện bằng cách lưu trữ kết quả của các bài toán con đã được giải quyết. Điều này đặc biệt hữu ích trong các bài toán có tính chất lặp lại, như dãy Fibonacci hay bài toán tối ưu hóa.
- Giải quyết được các bài toán phức tạp: Quy hoạch động cho phép giải quyết nhiều bài toán tối ưu hóa và lập lịch phức tạp mà các phương pháp khác có thể không hiệu quả, chẳng hạn như bài toán balo (knapsack problem), chuỗi con chung dài nhất (Longest Common Subsequence - LCS), và nhiều bài toán liên quan đến đồ thị.
- Tránh các tính toán lặp lại không cần thiết: Bằng cách lưu trữ kết quả của các bài toán con, quy hoạch động tránh việc tính toán lặp lại những phần đã giải quyết, giúp tiết kiệm tài nguyên và tăng hiệu suất.
- Độ chính xác cao: Kỹ thuật quy hoạch động đảm bảo tìm ra giải pháp tối ưu cho bài toán bằng cách xây dựng các giải pháp từ các bài toán con tối ưu, đảm bảo tính chính xác trong kết quả cuối cùng.
Nhược điểm:
- Tốn bộ nhớ: Quy hoạch động yêu cầu lưu trữ kết quả của tất cả các bài toán con, điều này có thể tiêu tốn rất nhiều bộ nhớ, đặc biệt đối với các bài toán có không gian trạng thái lớn.
- Phức tạp trong việc triển khai: Việc hiểu và triển khai một giải pháp quy hoạch động đòi hỏi phải nắm rõ cấu trúc của bài toán và cách chia nhỏ nó thành các bài toán con.
- Không phải lúc nào cũng khả thi: Không phải bài toán nào cũng có thể áp dụng quy hoạch động. Các bài toán cần có tính chất con tối ưu (optimal substructure) và tính chất lặp lại của bài toán con (overlapping subproblems). Nếu bài toán không có các tính chất này, quy hoạch động sẽ không hiệu quả.
- Tiêu tốn thời gian cho việc lưu trữ và truy xuất: Mặc dù quy hoạch động giảm thời gian tính toán, việc lưu trữ và truy xuất kết quả từ bộ nhớ cũng tiêu tốn thời gian, đặc biệt khi kích thước của bảng lưu trữ lớn.
5. Kết luận
Cấu trúc dữ liệu và giải thuật là kiến thức nền tảng không thể thiếu cho bất kỳ ai muốn trở thành một lập trình viên giỏi. Việc nắm vững chúng không chỉ giúp bạn viết ra những đoạn mã hiệu quả, tối ưu hơn mà còn rèn luyện tư duy logic và khả năng giải quyết vấn đề một cách có hệ thống.
Các bài viết liên quan tại Blog 200Lab:
- OOP là gì? Chi tiết về lập trình hướng đối tượng
- Đệ Quy là gì? Có bao nhiêu loại Đệ Quy cơ bản?
- Tối ưu ứng dụng với cấu trúc dữ liệu cơ bản và bitwise
- gRPC là gì? Vũ khí tối thượng tăng tải Microservices